
1. What is the projected Compound Annual Growth Rate (CAGR) of the Synthetic Data Tool?
The projected CAGR is approximately XX%.
MR Forecast provides premium market intelligence on deep technologies that can cause a high level of disruption in the market within the next few years. When it comes to doing market viability analyses for technologies at very early phases of development, MR Forecast is second to none. What sets us apart is our set of market estimates based on secondary research data, which in turn gets validated through primary research by key companies in the target market and other stakeholders. It only covers technologies pertaining to Healthcare, IT, big data analysis, block chain technology, Artificial Intelligence (AI), Machine Learning (ML), Internet of Things (IoT), Energy & Power, Automobile, Agriculture, Electronics, Chemical & Materials, Machinery & Equipment's, Consumer Goods, and many others at MR Forecast. Market: The market section introduces the industry to readers, including an overview, business dynamics, competitive benchmarking, and firms' profiles. This enables readers to make decisions on market entry, expansion, and exit in certain nations, regions, or worldwide. Application: We give painstaking attention to the study of every product and technology, along with its use case and user categories, under our research solutions. From here on, the process delivers accurate market estimates and forecasts apart from the best and most meaningful insights.
Products generically come under this phrase and may imply any number of goods, components, materials, technology, or any combination thereof. Any business that wants to push an innovative agenda needs data on product definitions, pricing analysis, benchmarking and roadmaps on technology, demand analysis, and patents. Our research papers contain all that and much more in a depth that makes them incredibly actionable. Products broadly encompass a wide range of goods, components, materials, technologies, or any combination thereof. For businesses aiming to advance an innovative agenda, access to comprehensive data on product definitions, pricing analysis, benchmarking, technological roadmaps, demand analysis, and patents is essential. Our research papers provide in-depth insights into these areas and more, equipping organizations with actionable information that can drive strategic decision-making and enhance competitive positioning in the market.
 Synthetic Data Tool
Synthetic Data ToolSynthetic Data Tool by Type (On-premises, Cloud Based), by Application (Data Scientist, Data Engineer, Others), by North America (United States, Canada, Mexico), by South America (Brazil, Argentina, Rest of South America), by Europe (United Kingdom, Germany, France, Italy, Spain, Russia, Benelux, Nordics, Rest of Europe), by Middle East & Africa (Turkey, Israel, GCC, North Africa, South Africa, Rest of Middle East & Africa), by Asia Pacific (China, India, Japan, South Korea, ASEAN, Oceania, Rest of Asia Pacific) Forecast 2025-2033

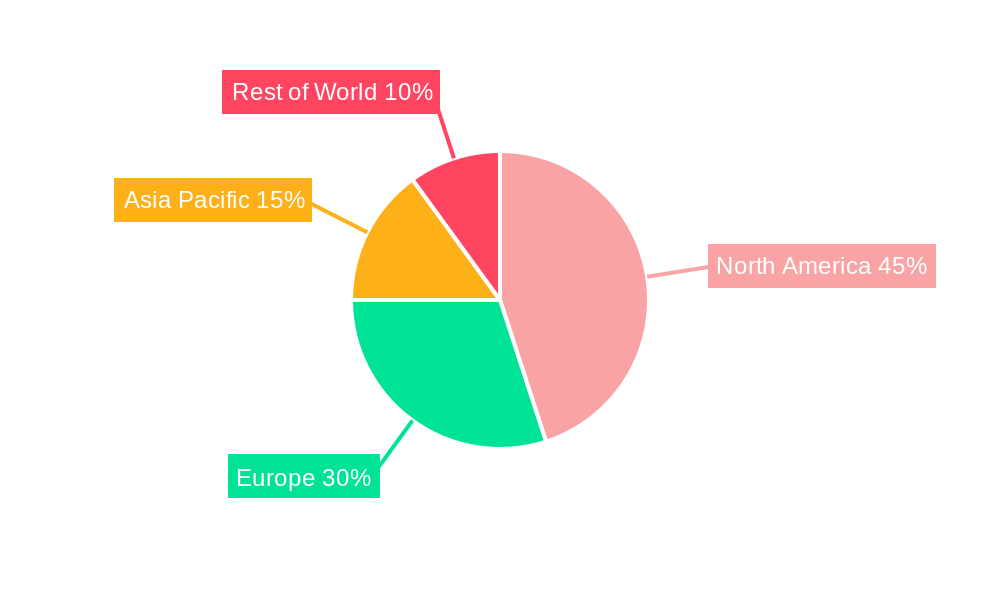
The synthetic data tool market is experiencing rapid growth, driven by the increasing need for high-quality data in artificial intelligence (AI) and machine learning (ML) applications. The market's expansion is fueled by several factors, including the rising demand for data privacy and security, the increasing complexity of AI models requiring large datasets, and the limitations of real-world data acquisition. We estimate the 2025 market size to be around $1.5 billion, with a compound annual growth rate (CAGR) of 25% projected through 2033. This significant growth is attributed to the expanding adoption of synthetic data across various industries, including finance, healthcare, and automotive. The on-premises deployment model currently holds a larger market share, but the cloud-based segment is poised for rapid growth due to its scalability and cost-effectiveness. Data scientists are the primary users, but the demand is expanding to data engineers and other roles requiring data analysis. Key regional markets include North America and Europe, driven by the presence of major technology companies and a robust AI ecosystem. However, Asia-Pacific is expected to witness the fastest growth in the coming years due to increasing digitalization and government initiatives promoting AI adoption.
The competitive landscape is dynamic, with numerous companies offering a variety of solutions catering to different needs and scales. Established players like Datagen and Parallel Domain are competing with emerging companies like Synthesis AI and Hazy, each specializing in specific synthetic data generation techniques. The market is witnessing innovation in the types of data generated (image, text, tabular) and the sophistication of the generation algorithms. This competitive environment is driving innovation and creating opportunities for smaller players to specialize and carve out niches. The key restraints to market growth include the challenges associated with ensuring the quality and realism of synthetic data, and the need for greater understanding and acceptance of this technology among non-technical users. Addressing these challenges will be crucial for sustained market growth in the long term. The market is segmented by deployment (on-premises, cloud-based), application (data scientist, data engineer, others), and geography, allowing for targeted strategies and growth opportunities.
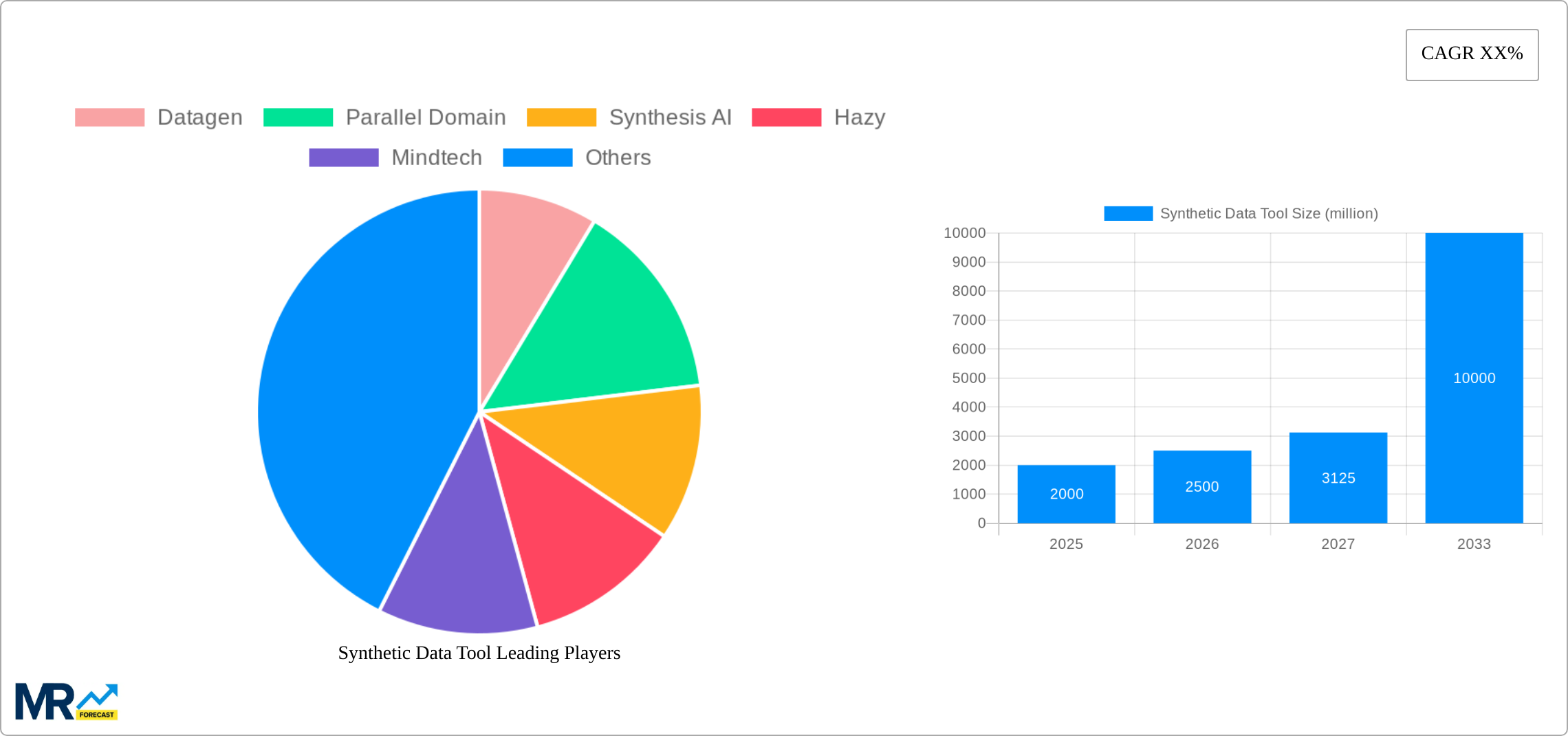
The synthetic data tool market is experiencing explosive growth, projected to reach USD XXX million by 2033, from USD XXX million in 2025. The historical period (2019-2024) witnessed a steady rise in adoption, driven by increasing concerns around data privacy regulations like GDPR and CCPA, coupled with the rising need for large, high-quality datasets for training AI/ML models. This trend is expected to continue throughout the forecast period (2025-2033), fueled by advancements in synthetic data generation techniques, particularly generative adversarial networks (GANs) and variational autoencoders (VAEs). The market is witnessing a shift from primarily on-premises solutions towards cloud-based offerings, driven by scalability and cost-effectiveness. Furthermore, the ease of use and accessibility of these tools are attracting a wider range of users beyond traditional data scientists and engineers, including business analysts and domain experts. The increasing sophistication of synthetic data, allowing for the creation of datasets that closely mimic real-world data while preserving privacy, is a key driver of market expansion. Specific applications are broadening, with synthetic data being leveraged across diverse sectors such as healthcare, finance, and autonomous driving, further propelling market growth. The competition is intensifying, with both established players and new entrants vying for market share, leading to innovation and price competition. This dynamic market landscape is poised for significant expansion over the next decade, with continued advancements in technology and wider industry adoption.
Several factors are converging to propel the rapid growth of the synthetic data tool market. The stringent data privacy regulations, such as GDPR and CCPA, significantly restrict the use of real-world data, especially for sensitive applications. Synthetic data offers a viable alternative, enabling organizations to train and test their AI/ML models without compromising privacy. The increasing demand for high-quality training data for sophisticated AI and machine learning models is another key driver. Generating massive, accurately labeled datasets for training AI is often expensive and time-consuming. Synthetic data tools offer a cost-effective and efficient solution, allowing for the creation of datasets tailored to specific needs. Furthermore, the advancements in generative models, like GANs and VAEs, have significantly improved the quality and realism of synthetic data, making it increasingly suitable for diverse applications. The ability to control the characteristics of synthetic data allows for targeted experimentation and bias mitigation, which appeals to researchers and developers. Finally, the growing adoption of cloud-based solutions provides scalable and accessible platforms for creating and utilizing synthetic data, further boosting market growth.
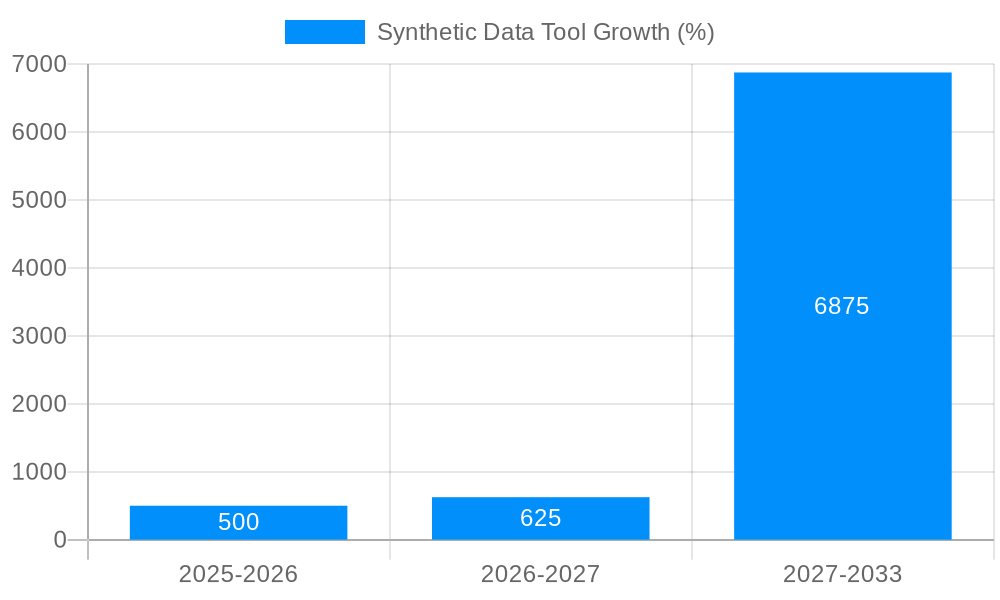
Despite the significant growth potential, the synthetic data tool market faces certain challenges. The quality of synthetic data remains a critical concern. While advancements have improved realism, replicating the nuances and complexities of real-world data perfectly remains a challenge. Ensuring that the synthetic data accurately reflects the statistical properties of the target data distribution is crucial for reliable model training. The lack of standardization in synthetic data generation techniques and evaluation metrics can create inconsistencies and hinder the comparison of different tools. This makes it difficult for users to assess the quality and suitability of various synthetic data generation solutions. Moreover, the computational cost associated with generating high-quality synthetic data, especially for complex datasets, can be substantial, potentially limiting its accessibility to smaller organizations. Finally, educating and gaining trust from users on the validity and reliability of synthetic data in real-world applications remains a significant challenge. Addressing these concerns is vital for realizing the full potential of the synthetic data market.
The cloud-based segment is projected to dominate the synthetic data tool market during the forecast period. This dominance stems from the inherent advantages of cloud-based solutions, including scalability, cost-effectiveness, and accessibility. Cloud platforms provide the necessary computing power for generating large synthetic datasets, making them ideal for large-scale AI/ML projects. Furthermore, the ease of integration with other cloud-based services and the pay-as-you-go pricing model make cloud-based synthetic data tools an attractive option for businesses of all sizes.
The Data Scientist application segment is also expected to be a major contributor to market growth. Data scientists rely heavily on large, high-quality datasets to train and evaluate their models. Synthetic data addresses several key limitations in traditional data sources, providing the flexibility and control needed for effective model development and validation.
The convergence of increasing demand for AI/ML model training data, stringent data privacy regulations, and advancements in synthetic data generation techniques are collectively fueling significant growth in the synthetic data tool industry. The ability to create large, high-quality, privacy-preserving datasets is revolutionizing various sectors, enabling data-driven innovations while mitigating risks associated with real-world data.
This report provides a comprehensive overview of the synthetic data tool market, analyzing market trends, growth drivers, challenges, and key players. It offers valuable insights for businesses looking to leverage synthetic data for AI/ML development and for investors seeking opportunities in this rapidly expanding sector. The report's detailed segmentation and regional analysis help identify key growth opportunities and potential risks. With its detailed forecast and analysis of major industry players, this report serves as an essential resource for strategic decision-making in the synthetic data tool market.
| Aspects | Details |
|---|---|
| Study Period | 2019-2033 |
| Base Year | 2024 |
| Estimated Year | 2025 |
| Forecast Period | 2025-2033 |
| Historical Period | 2019-2024 |
| Growth Rate | CAGR of XX% from 2019-2033 |
| Segmentation |
|




Note*: In applicable scenarios
Primary Research
Secondary Research

Involves using different sources of information in order to increase the validity of a study
These sources are likely to be stakeholders in a program - participants, other researchers, program staff, other community members, and so on.
Then we put all data in single framework & apply various statistical tools to find out the dynamic on the market.
During the analysis stage, feedback from the stakeholder groups would be compared to determine areas of agreement as well as areas of divergence
The projected CAGR is approximately XX%.
Key companies in the market include Datagen, Parallel Domain, Synthesis AI, Hazy, Mindtech, CVEDIA, Edgecase.ai, Statice, Oneview, Ydata, SKY ENGINE AI, MOSTLY AI, ANYVERSE, Facteus, Gretel, Syntheticus, Datomize, Synthesized, Rendered.ai, Syntho, Clearbox AI, Tonic, .
The market segments include Type, Application.
The market size is estimated to be USD XXX million as of 2022.
N/A
N/A
N/A
N/A
Pricing options include single-user, multi-user, and enterprise licenses priced at USD 3480.00, USD 5220.00, and USD 6960.00 respectively.
The market size is provided in terms of value, measured in million.
Yes, the market keyword associated with the report is "Synthetic Data Tool," which aids in identifying and referencing the specific market segment covered.
The pricing options vary based on user requirements and access needs. Individual users may opt for single-user licenses, while businesses requiring broader access may choose multi-user or enterprise licenses for cost-effective access to the report.
While the report offers comprehensive insights, it's advisable to review the specific contents or supplementary materials provided to ascertain if additional resources or data are available.
To stay informed about further developments, trends, and reports in the Synthetic Data Tool, consider subscribing to industry newsletters, following relevant companies and organizations, or regularly checking reputable industry news sources and publications.