
1. What is the projected Compound Annual Growth Rate (CAGR) of the Synthetic Data Tool?
The projected CAGR is approximately XX%.
MR Forecast provides premium market intelligence on deep technologies that can cause a high level of disruption in the market within the next few years. When it comes to doing market viability analyses for technologies at very early phases of development, MR Forecast is second to none. What sets us apart is our set of market estimates based on secondary research data, which in turn gets validated through primary research by key companies in the target market and other stakeholders. It only covers technologies pertaining to Healthcare, IT, big data analysis, block chain technology, Artificial Intelligence (AI), Machine Learning (ML), Internet of Things (IoT), Energy & Power, Automobile, Agriculture, Electronics, Chemical & Materials, Machinery & Equipment's, Consumer Goods, and many others at MR Forecast. Market: The market section introduces the industry to readers, including an overview, business dynamics, competitive benchmarking, and firms' profiles. This enables readers to make decisions on market entry, expansion, and exit in certain nations, regions, or worldwide. Application: We give painstaking attention to the study of every product and technology, along with its use case and user categories, under our research solutions. From here on, the process delivers accurate market estimates and forecasts apart from the best and most meaningful insights.
Products generically come under this phrase and may imply any number of goods, components, materials, technology, or any combination thereof. Any business that wants to push an innovative agenda needs data on product definitions, pricing analysis, benchmarking and roadmaps on technology, demand analysis, and patents. Our research papers contain all that and much more in a depth that makes them incredibly actionable. Products broadly encompass a wide range of goods, components, materials, technologies, or any combination thereof. For businesses aiming to advance an innovative agenda, access to comprehensive data on product definitions, pricing analysis, benchmarking, technological roadmaps, demand analysis, and patents is essential. Our research papers provide in-depth insights into these areas and more, equipping organizations with actionable information that can drive strategic decision-making and enhance competitive positioning in the market.
 Synthetic Data Tool
Synthetic Data ToolSynthetic Data Tool by Type (On-premises, Cloud Based), by Application (Data Scientist, Data Engineer, Others), by North America (United States, Canada, Mexico), by South America (Brazil, Argentina, Rest of South America), by Europe (United Kingdom, Germany, France, Italy, Spain, Russia, Benelux, Nordics, Rest of Europe), by Middle East & Africa (Turkey, Israel, GCC, North Africa, South Africa, Rest of Middle East & Africa), by Asia Pacific (China, India, Japan, South Korea, ASEAN, Oceania, Rest of Asia Pacific) Forecast 2025-2033

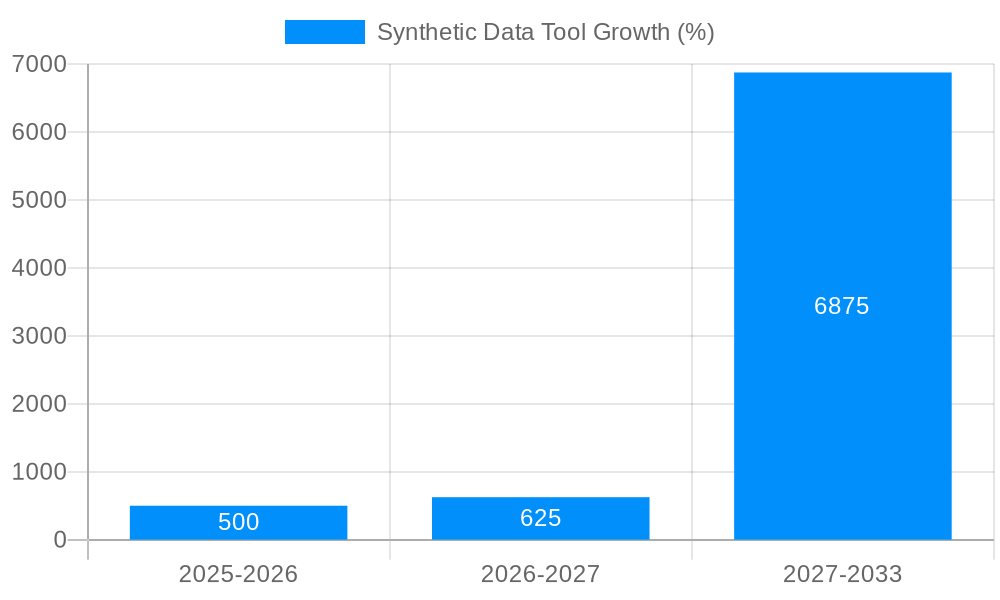
The synthetic data market is experiencing robust growth, driven by the increasing need for high-quality data in machine learning and AI development, especially in sectors facing data privacy and scarcity challenges. The market, estimated at $2 billion in 2025, is projected to achieve a compound annual growth rate (CAGR) of 25% through 2033, reaching an estimated $10 billion by then. This expansion is fueled by several key factors: the rising adoption of cloud-based solutions offering scalability and accessibility, the growing demand from data scientists and engineers for efficient data generation tools, and the increasing regulatory scrutiny around personally identifiable information (PII), promoting synthetic data as a privacy-preserving alternative. Significant market segmentation exists, with the cloud-based segment anticipated to dominate due to its inherent flexibility and cost-effectiveness. Furthermore, the application of synthetic data is widening beyond data science and engineering, penetrating diverse fields including marketing and simulation testing, contributing significantly to market growth.
Key players in the synthetic data tools market are continuously innovating, introducing advanced algorithms and features that enhance the realism and utility of synthetic datasets. However, market penetration is still challenged by factors like the perceived complexity of implementing these tools, the need for specialized expertise in data science and AI, and the initial investment costs. Regional adoption patterns reflect the global technological maturity, with North America and Europe currently leading in market share, but significant opportunities exist in rapidly developing economies within Asia Pacific and other regions. Future growth will likely be propelled by advancements in generative AI and further improvements in the quality and diversity of synthetic data generated, along with wider industry awareness and understanding of the benefits of synthetic data.
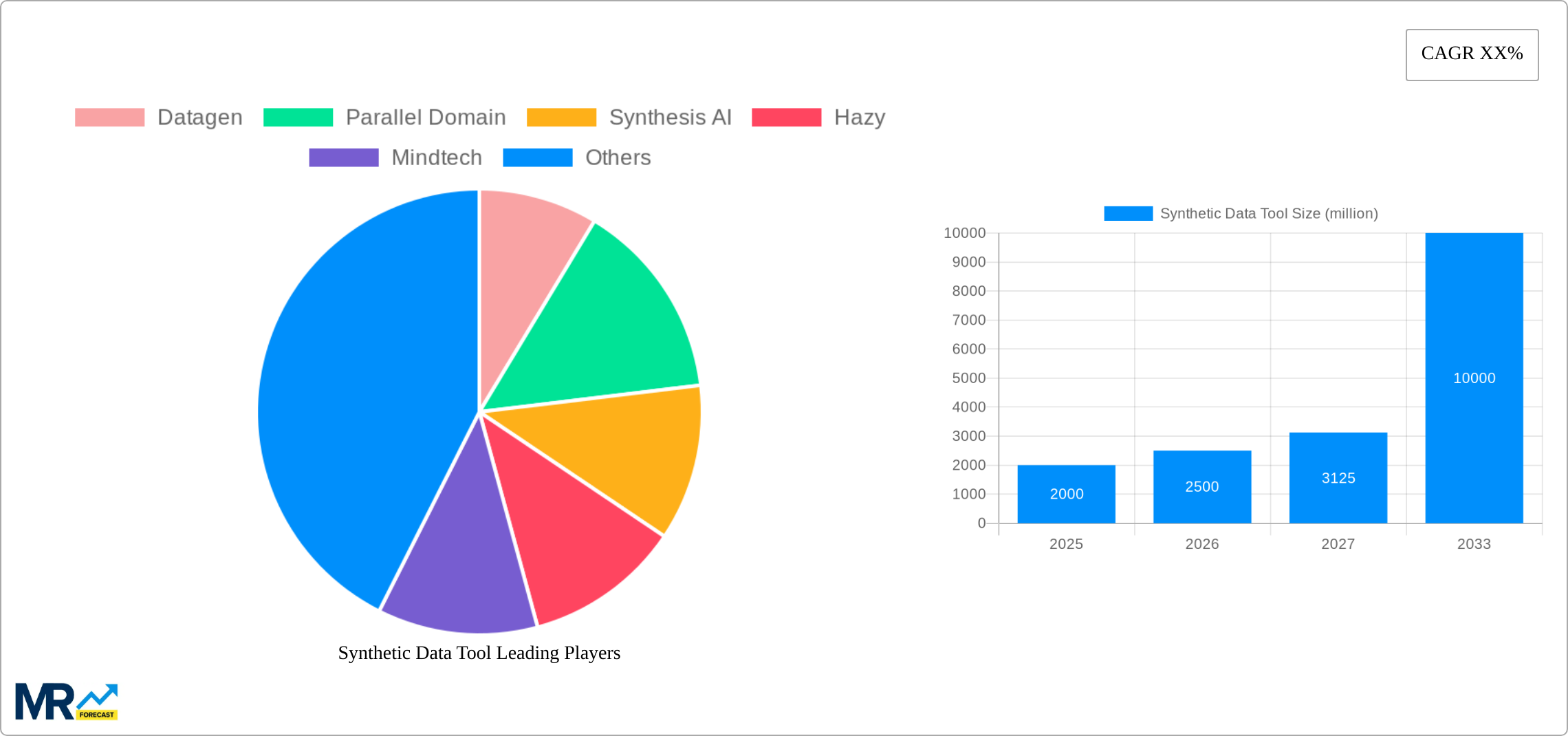
The synthetic data tool market is experiencing explosive growth, projected to reach multi-billion dollar valuations by 2033. Our study, covering the period from 2019 to 2033, with a base year of 2025 and an estimated year of 2025, reveals a compound annual growth rate (CAGR) exceeding expectations. The historical period (2019-2024) showed significant initial adoption, primarily driven by the increasing need for large, high-quality datasets in AI and machine learning applications. This demand is outpacing the availability of real-world data, which is often expensive, difficult to obtain, and subject to privacy regulations. Synthetic data, offering a viable alternative, has become a cornerstone for training and testing AI models, especially in sensitive sectors like healthcare and finance. The market's expansion is fueled by advancements in generative models, improved data synthesis techniques, and the rising adoption of cloud-based solutions. This trend is expected to continue throughout the forecast period (2025-2033), with the market expanding across various industries and application domains. The estimated market value in 2025 is in the billions, signifying a major shift in data management and AI model development. The increasing sophistication of synthetic data generation, allowing for the creation of datasets that mimic the complexities of real-world scenarios with high fidelity, will be a key factor in driving this growth. Furthermore, the development of specialized tools and platforms catering to diverse user needs, from data scientists to non-technical users, will further propel market expansion in the coming years. The rise of synthetic data is not just a trend; it's a fundamental transformation in how data is managed and utilized for artificial intelligence applications. The market is anticipated to exceed several billion dollars by the end of our forecast period, driven by robust growth and increased adoption across diverse applications and industries.
Several key factors are propelling the rapid expansion of the synthetic data tool market. Firstly, the burgeoning field of artificial intelligence and machine learning necessitates massive datasets for model training and validation. Real-world data acquisition is often constrained by cost, time, and privacy regulations, making synthetic data a crucial solution. Secondly, the increasing prevalence of data privacy regulations, such as GDPR and CCPA, is limiting access to sensitive real-world data. Synthetic data provides a compliant alternative, allowing organizations to develop and test AI models without compromising privacy. Thirdly, the advancements in generative models and algorithms have significantly improved the quality and realism of synthetic data, making it increasingly suitable for complex AI tasks. Moreover, the rise of cloud computing has facilitated easier access to powerful computing resources required for generating and managing large synthetic datasets. Finally, the expanding range of applications for synthetic data, encompassing various industries like healthcare, finance, and autonomous vehicles, is widening the market's scope and fueling further investment and innovation. The convergence of these factors creates a synergistic effect, driving the market's substantial growth and positioning synthetic data as a critical component of the modern data landscape.
Despite its potential, the synthetic data tool market faces several challenges. One major hurdle is the need for robust validation techniques to ensure the quality and fidelity of synthetic data. Ensuring that synthetic data accurately reflects the statistical properties and patterns of real-world data is crucial for reliable model training and deployment. This requires sophisticated validation methods and potentially human review, which can increase costs and development time. Another challenge lies in the complexity of generating high-quality synthetic data, especially for complex scenarios and specific domains. Developing algorithms that can capture nuanced characteristics and dependencies within data can be computationally intensive and require specialized expertise. Furthermore, the market's relative novelty and the constant evolution of data generation techniques pose challenges for standardization and interoperability. Different tools and platforms may use various formats and methods, hindering seamless data exchange and integration. Finally, the acceptance and trust in synthetic data by industry stakeholders remain a concern. Demonstrating the validity and reliability of synthetic data for critical applications is essential for broader adoption. Overcoming these hurdles through continuous innovation, standardization efforts, and rigorous validation protocols will be crucial for the sustained growth of the synthetic data tool market.
The cloud-based segment is poised to dominate the synthetic data tool market throughout the forecast period. Cloud-based solutions offer scalability, flexibility, and cost-effectiveness, making them particularly attractive to organizations of all sizes. This segment's dominance is fueled by the rising adoption of cloud computing infrastructure and services globally, particularly in regions with strong technological advancements.
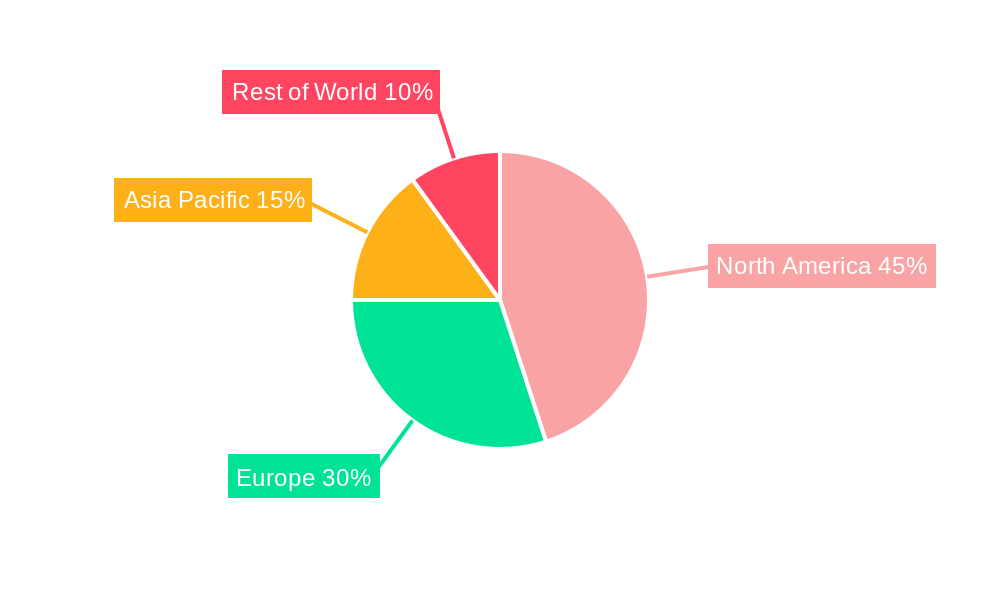
North America: This region is expected to lead the market, driven by high adoption of AI and machine learning technologies, along with a robust technology infrastructure and increased investment in research and development. The presence of major technology companies and a large number of startups in the synthetic data space further strengthens this region's leading position.
Europe: While slightly behind North America, Europe is expected to witness significant growth, driven by the strong emphasis on data privacy regulations (like GDPR) and the increasing awareness of the benefits of synthetic data. This regulatory landscape is promoting the adoption of synthetic data as a means to comply with privacy regulations while still benefiting from the power of AI.
Asia-Pacific: This region exhibits promising growth potential, fueled by rapid technological advancements, increasing investment in AI, and a large pool of tech-savvy professionals. However, regulatory hurdles and infrastructural limitations in some areas may pose challenges to market penetration.
Cloud-Based Segment Dominance: The ease of access, scalability, and cost-effectiveness of cloud-based synthetic data tools contribute significantly to their market dominance. Cloud platforms provide the necessary computational power and storage capacity to handle the large datasets involved in synthetic data generation, appealing to a broad range of users from small startups to large enterprises. The convenience and pay-as-you-go pricing models further enhance the appeal of cloud-based solutions in this growing market.
The Data Scientist application segment also holds a significant share due to their crucial role in designing, developing, and utilizing synthetic datasets for AI model development and validation. Data Scientists are the key users driving the demand for advanced tools and features in synthetic data solutions.
The growth of the synthetic data tool industry is significantly propelled by the increasing need for data privacy protection, the escalating demand for high-quality data for training AI/ML models, and continuous advancements in data synthesis technology. These factors combine to create a strong market momentum, driving further innovation and adoption of synthetic data solutions. The growing availability of sophisticated tools and user-friendly interfaces is also playing a key role in fostering wider accessibility and adoption.
This report offers a comprehensive overview of the synthetic data tool market, analyzing key trends, drivers, challenges, and growth opportunities. The in-depth analysis provides valuable insights for market participants, including vendors, investors, and researchers, enabling informed decision-making in this rapidly evolving landscape. The projections are based on rigorous market research and detailed financial modelling, offering a reliable forecast for the years to come.
| Aspects | Details |
|---|---|
| Study Period | 2019-2033 |
| Base Year | 2024 |
| Estimated Year | 2025 |
| Forecast Period | 2025-2033 |
| Historical Period | 2019-2024 |
| Growth Rate | CAGR of XX% from 2019-2033 |
| Segmentation |
|




Note*: In applicable scenarios
Primary Research
Secondary Research

Involves using different sources of information in order to increase the validity of a study
These sources are likely to be stakeholders in a program - participants, other researchers, program staff, other community members, and so on.
Then we put all data in single framework & apply various statistical tools to find out the dynamic on the market.
During the analysis stage, feedback from the stakeholder groups would be compared to determine areas of agreement as well as areas of divergence
The projected CAGR is approximately XX%.
Key companies in the market include Datagen, Parallel Domain, Synthesis AI, Hazy, Mindtech, CVEDIA, Edgecase.ai, Statice, Oneview, Ydata, SKY ENGINE AI, MOSTLY AI, ANYVERSE, Facteus, Gretel, Syntheticus, Datomize, Synthesized, Rendered.ai, Syntho, Clearbox AI, Tonic, .
The market segments include Type, Application.
The market size is estimated to be USD XXX million as of 2022.
N/A
N/A
N/A
N/A
Pricing options include single-user, multi-user, and enterprise licenses priced at USD 4480.00, USD 6720.00, and USD 8960.00 respectively.
The market size is provided in terms of value, measured in million.
Yes, the market keyword associated with the report is "Synthetic Data Tool," which aids in identifying and referencing the specific market segment covered.
The pricing options vary based on user requirements and access needs. Individual users may opt for single-user licenses, while businesses requiring broader access may choose multi-user or enterprise licenses for cost-effective access to the report.
While the report offers comprehensive insights, it's advisable to review the specific contents or supplementary materials provided to ascertain if additional resources or data are available.
To stay informed about further developments, trends, and reports in the Synthetic Data Tool, consider subscribing to industry newsletters, following relevant companies and organizations, or regularly checking reputable industry news sources and publications.