
1. What is the projected Compound Annual Growth Rate (CAGR) of the Data De-identification & Pseudonymity Software?
The projected CAGR is approximately XX%.
MR Forecast provides premium market intelligence on deep technologies that can cause a high level of disruption in the market within the next few years. When it comes to doing market viability analyses for technologies at very early phases of development, MR Forecast is second to none. What sets us apart is our set of market estimates based on secondary research data, which in turn gets validated through primary research by key companies in the target market and other stakeholders. It only covers technologies pertaining to Healthcare, IT, big data analysis, block chain technology, Artificial Intelligence (AI), Machine Learning (ML), Internet of Things (IoT), Energy & Power, Automobile, Agriculture, Electronics, Chemical & Materials, Machinery & Equipment's, Consumer Goods, and many others at MR Forecast. Market: The market section introduces the industry to readers, including an overview, business dynamics, competitive benchmarking, and firms' profiles. This enables readers to make decisions on market entry, expansion, and exit in certain nations, regions, or worldwide. Application: We give painstaking attention to the study of every product and technology, along with its use case and user categories, under our research solutions. From here on, the process delivers accurate market estimates and forecasts apart from the best and most meaningful insights.
Products generically come under this phrase and may imply any number of goods, components, materials, technology, or any combination thereof. Any business that wants to push an innovative agenda needs data on product definitions, pricing analysis, benchmarking and roadmaps on technology, demand analysis, and patents. Our research papers contain all that and much more in a depth that makes them incredibly actionable. Products broadly encompass a wide range of goods, components, materials, technologies, or any combination thereof. For businesses aiming to advance an innovative agenda, access to comprehensive data on product definitions, pricing analysis, benchmarking, technological roadmaps, demand analysis, and patents is essential. Our research papers provide in-depth insights into these areas and more, equipping organizations with actionable information that can drive strategic decision-making and enhance competitive positioning in the market.
 Data De-identification & Pseudonymity Software
Data De-identification & Pseudonymity SoftwareData De-identification & Pseudonymity Software by Type (Cloud-Based, On-Premises), by Application (Individual, Enterprise, Others), by North America (United States, Canada, Mexico), by South America (Brazil, Argentina, Rest of South America), by Europe (United Kingdom, Germany, France, Italy, Spain, Russia, Benelux, Nordics, Rest of Europe), by Middle East & Africa (Turkey, Israel, GCC, North Africa, South Africa, Rest of Middle East & Africa), by Asia Pacific (China, India, Japan, South Korea, ASEAN, Oceania, Rest of Asia Pacific) Forecast 2025-2033

The data de-identification and pseudonymity software market is anticipated to grow from USD 1882.1 million in 2025 to USD 9,415.3 million by 2033, registering a CAGR of 24.3% from 2025 to 2033. Key factors driving the growth of the market include the increasing adoption of cloud-based solutions, the growing demand for data privacy and security, and the increasing number of data breaches.
Cloud-based solutions are becoming increasingly popular as they offer a number of advantages over on-premises solutions, such as scalability, flexibility, and cost-effectiveness. Data privacy and security concerns are also driving the growth of the market, as businesses are becoming increasingly aware of the importance of protecting customer data. The increasing number of data breaches is also prompting businesses to invest in data de-identification and pseudonymity software to protect their data from unauthorized access. The market is segmented by type, application, and region. By type, the market is segmented into cloud-based and on-premises solutions. By application, the market is segmented into individual, enterprise, and others. By region, the market is segmented into North America, South America, Europe, Middle East & Africa, and Asia Pacific.
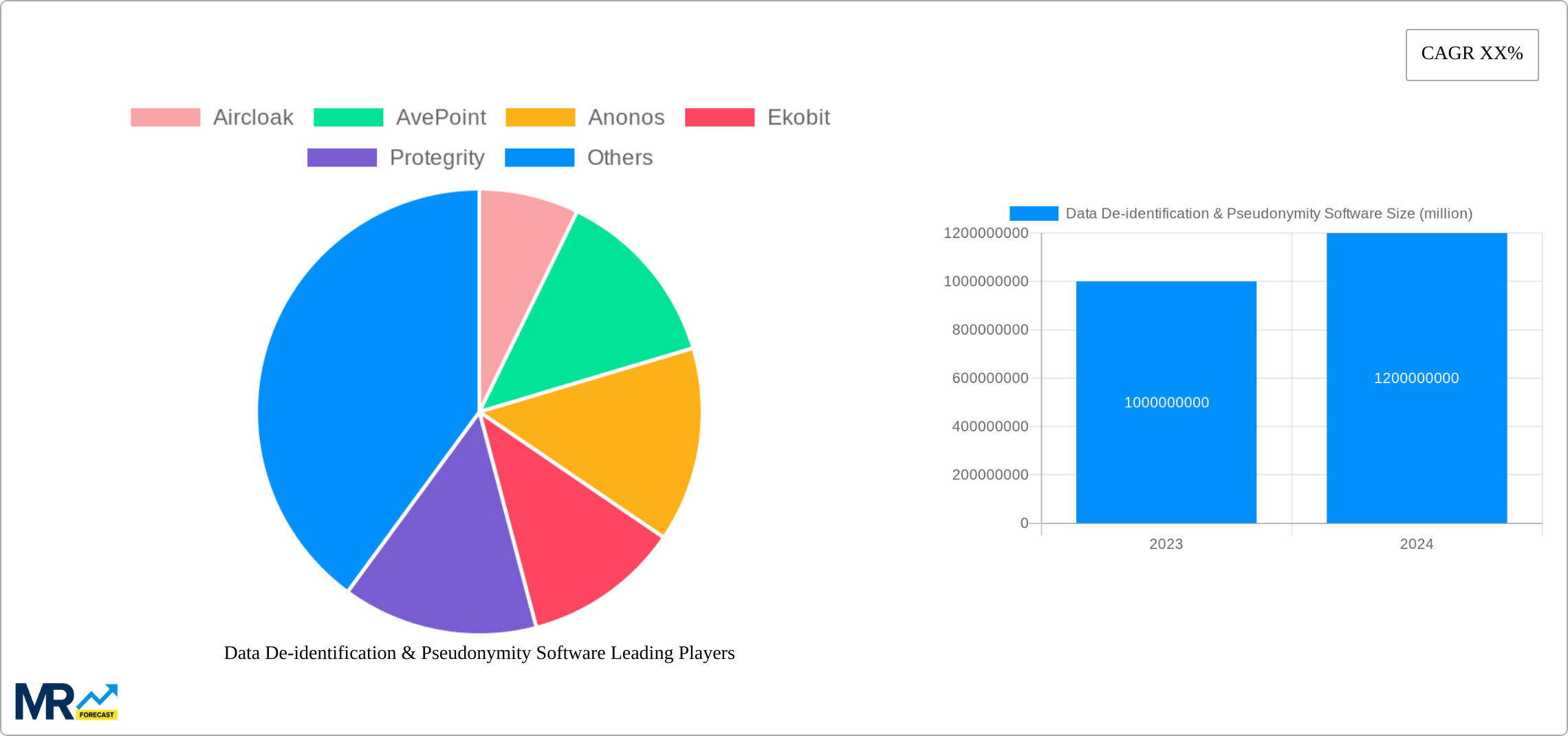
The global data de-identification and pseudonymity software market is estimated to reach USD 1.21 billion by 2025, registering a CAGR of 13.8% during the forecast period. The increasing demand for data privacy and protection measures across various industries is driving the growth of the market.
Government regulations, such as the General Data Protection Regulation (GDPR) in the European Union and the California Consumer Privacy Act (CCPA) in the United States, necessitate organizations to implement robust data protection measures. This has led to an increased adoption of data de-identification and pseudonymity software, as these tools enable organizations to anonymize their data while preserving its utility for analytics, research, and other purposes.
The rising awareness of data breaches and cyberattacks has raised concerns among organizations about the security of their data. Data de-identification and pseudonymity software offer a cost-effective way to protect sensitive personal and financial data from unauthorized access. This, in turn, helps organizations maintain compliance with data privacy regulations and avoid potential legal penalties.
Moreover, the growing adoption of cloud computing has led to a significant increase in the volume and accessibility of data. As a result, organizations are looking for efficient ways to de-identify and pseudonymize large datasets to ensure data privacy while leveraging the benefits of cloud-based storage and analytics.
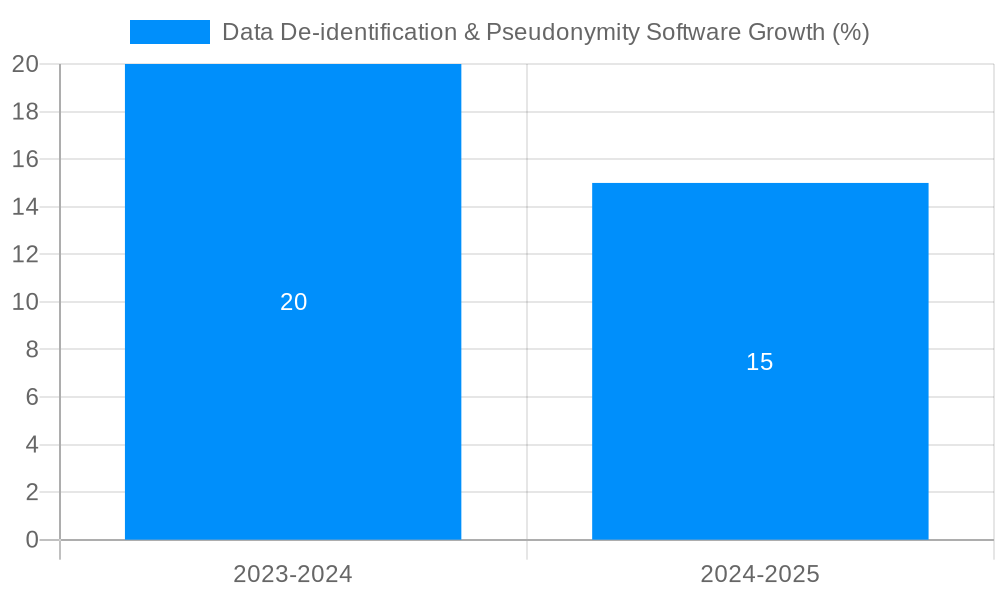
Despite the benefits, there are certain challenges associated with the adoption of data de-identification and pseudonymity software. One major challenge is the potential for inaccurate data de-identification. If data is not properly de-identified, it can still be linked to an individual, which can compromise their privacy.
Another challenge is the performance overhead associated with data de-identification. This means that it can significantly slow down the processing of data analytics and machine learning tasks.
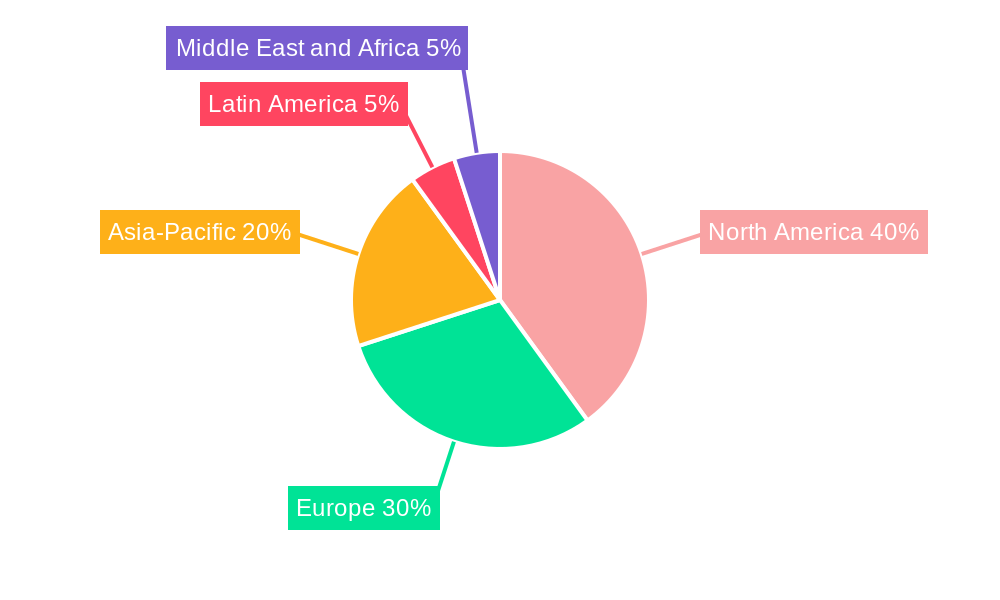
North America is expected to hold the largest share of the data de-identification and pseudonymity software market throughout the forecast period. This region has a large number of large enterprises that are investing heavily in data privacy technologies. Additionally, the strong regulatory environment in North America, particularly in the United States, is driving the adoption of data de-identification and pseudonymity software.
The enterprise segment is expected to witness the highest growth in the market. Enterprises are increasingly recognizing the importance of data privacy and are implementing data de-identification and pseudonymity software to protect their sensitive data. Additionally, the rising number of data breaches is driving enterprises to invest in robust data protection measures.
The data de-identification and pseudonymity software industry is expected to grow significantly over the next few years. The following factors are expected to contribute to this growth:
Some of the leading players in the data de-identification and pseudonymity software market include:
The data de-identification and pseudonymity software sector is experiencing significant development. These include:
The comprehensive coverage data de-identification and pseudonymity software report provides an in-depth analysis of the market, including:
| Aspects | Details |
|---|---|
| Study Period | 2019-2033 |
| Base Year | 2024 |
| Estimated Year | 2025 |
| Forecast Period | 2025-2033 |
| Historical Period | 2019-2024 |
| Growth Rate | CAGR of XX% from 2019-2033 |
| Segmentation |
|




Note*: In applicable scenarios
Primary Research
Secondary Research

Involves using different sources of information in order to increase the validity of a study
These sources are likely to be stakeholders in a program - participants, other researchers, program staff, other community members, and so on.
Then we put all data in single framework & apply various statistical tools to find out the dynamic on the market.
During the analysis stage, feedback from the stakeholder groups would be compared to determine areas of agreement as well as areas of divergence
The projected CAGR is approximately XX%.
Key companies in the market include Aircloak, AvePoint, Anonos, Ekobit, Protegrity, Dataguise, Thales Group, ARCAD Software, IBM, MENTISoftware, Imperva, Informatica, KI DESIGN, Privacy Analytics, ContextSpace, Privitar, SecuPi, Semele, StratoKey, TokenEx, Truata, Very Good Security, Wizuda, .
The market segments include Type, Application.
The market size is estimated to be USD 1882.1 million as of 2022.
N/A
N/A
N/A
N/A
Pricing options include single-user, multi-user, and enterprise licenses priced at USD 4480.00, USD 6720.00, and USD 8960.00 respectively.
The market size is provided in terms of value, measured in million.
Yes, the market keyword associated with the report is "Data De-identification & Pseudonymity Software," which aids in identifying and referencing the specific market segment covered.
The pricing options vary based on user requirements and access needs. Individual users may opt for single-user licenses, while businesses requiring broader access may choose multi-user or enterprise licenses for cost-effective access to the report.
While the report offers comprehensive insights, it's advisable to review the specific contents or supplementary materials provided to ascertain if additional resources or data are available.
To stay informed about further developments, trends, and reports in the Data De-identification & Pseudonymity Software, consider subscribing to industry newsletters, following relevant companies and organizations, or regularly checking reputable industry news sources and publications.